
先日、食べログのユーザーレビュー評価点の算出アルゴリズム(計算方法)が開示されたことがニュースになった。開示とはいっても一般公開されたわけではなく、あくまで裁判の中で原告側(韓国料理チェーン「KollaBo」を運営する韓流村)に限定しての開示である。
韓流村が食べログの運営会社であるカカクコムを訴えたこの裁判でのKollaBo側の主張は、食べログ側がサイト内で表示を目立たせるための高額契約に誘導しようと、意図してKollaBoの評価点を不正に下げたというものだ。
そもそもユーザーレビューの評価はどのくらいビジネスに影響するのだろう。報道によれば、KollaBo全21店の評価点(5点満点)が平均で約0.2点下がり、これにより月間5000人、2500万円の売上減少につながったという。(割り算すれば客単価は約5,000円ということもわかる)
あらためて、ユーザー評価点という数字の影響力の大きさと、評価点の公平感を確保することの難しさが浮き彫りになっている。
食べログに限らず、Amazon、楽天市場といったECサイト、Yahooトラベルなどの旅行サイトでもユーザーの口コミ評価を点数で表示しているケースは多い。それだけ、他のユーザーがどう評価しているか、という情報が商品やサービスの選択にあたって重視されているということだろう。
実はその評価点は、みなさんが平均としてイメージする、各ユーザーの口コミ評価点の単純平均(算術平均とも呼ばれ、評価の単純合計を評価者数で割ったもの)にそもそもなっていない。なぜだろうか? あるいは単純平均では何がまずいのだろう?
実は単純平均ではないユーザー評価点
単純平均は計算方法もシンプルでわかりやすく、ユーザー評価の代表値(だいたい世間はどのように評価しているか)としてとても便利な値だ。反面、弱点もある。外れ値に弱いのだ。結果として、意図的にユーザー評価を高く見せるために、外食店側がサクラを雇って高評価を稼ぐ、あるいは競合店に対して意図的に低評価をつけるといった操作で平均値を上下させることが可能だ。ちなみに、同じ代表値でも中央値(データを降順に並べた際、順位が中央の値)は外れ値の影響を比較的受けにくいことはぜひ憶えておいてほしい。
また、このような意図的な操作がなかったとしても、評価が二分するような場合、残念ながら平均点からはそのような評価の散らばりや、好き嫌いが極端に分かれているといった状況は読み取れない。
単純平均は理解しやすく便利だと言えるが、一方で、データを平均値に集約する際、いろいろな情報が失われている、とも言える。
こういった単純平均の抱える課題を克服するために、多くのサイト運営者は評価値の計算方法(アルゴリズム)や評価点そのものの開示方法を工夫している。
まず、アルゴリズムから見てみよう。
アルゴリズムによる工夫
計算方法を開示すれば、その計算方法を逆手に取って評価を操作しようとすることが可能になるリスクがあることから、計算方法のアルゴリズムの詳細が開示されることはまずない。でもヒントはある。
評価点算出のアルゴリズムについて、例えば、Amazonでは以下のような説明がなされている
『全体的な星の評価と星ごとの割合の内訳を計算するために、単純な平均は使用されません。その代わり、レビューの日時がどれだけ新しいかや、レビューアーがAmazonで商品を購入したかどうかなどが考慮されます。また、レビューを分析して信頼性が検証されます。』
(「評価はどのように計算されますか?」 カスタマーレビューの説明から)
あるいは、当該の食べログでも評価については
『食べログの点数は、ユーザーの各評価を単純平均したものではありません。ユーザーに影響度を設定して、点数の算出要素の一つにしています。』
(食べログ「点数・ランキングについて」より)
と紹介されており、単純平均ではないことが明示されている。各ユーザーの評価を同等に扱うのではなく、ある種の重みを加味して加重平均的に評価していると考えられる。“ユーザー評価は平等ではない”ということだ。
このような計算方法が効いていると思われる実際のデータを食べログで見てみよう。
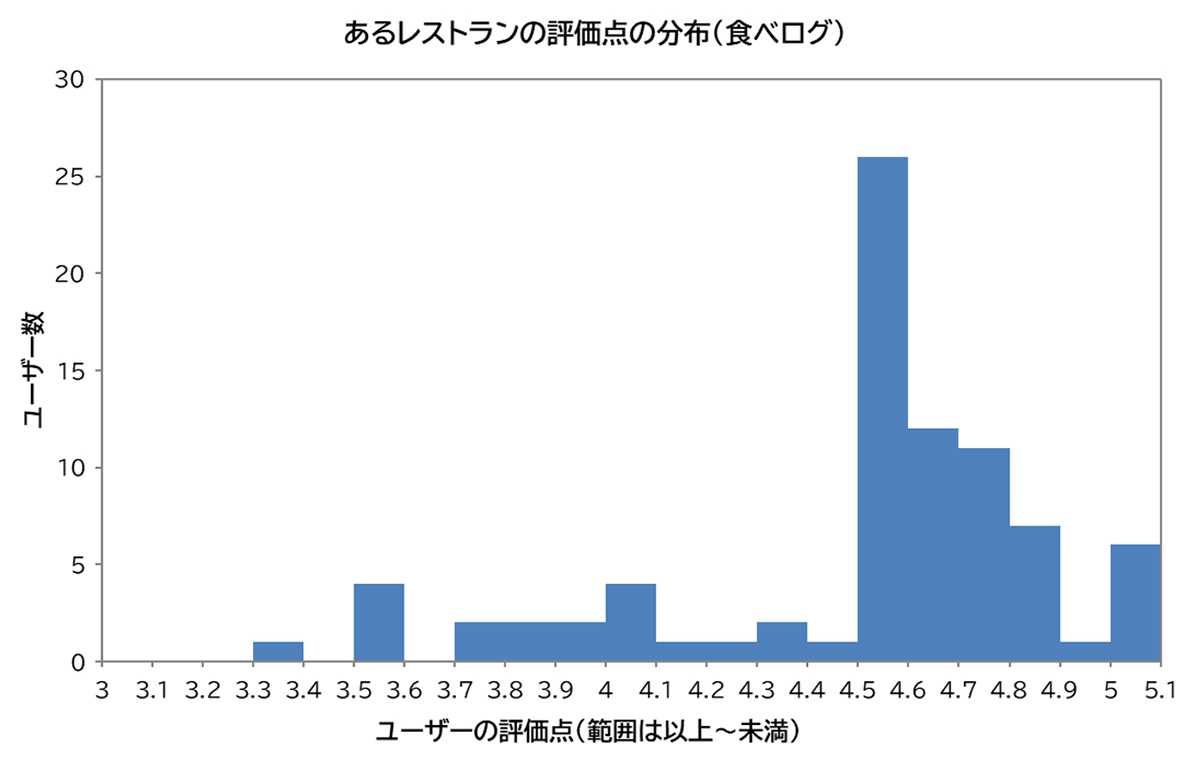
たまたま見つけたあるレストランの評価点は食べログ上では3.08点だが、手元で計算した評価点の単純平均は4.5点で大きな乖離がある。当該レストランの評価点の実際の分布はどうなっているだろうか。
ヒストグラムからわかるように、レストランの評価は4.5点を境に断層のように4.5点以上に評価点が集中しており、断定はできないが、評価の不自然さ(例えば外食店側による不正投稿などの可能性)がうかがえる。実はこのレストランでは3点未満の評価がないにもかかわらず評価点が3.08になっている。食べログの評価点の計算は、例えば怪しい評価に負の重みを与えるなどの形で、不自然な評価を織り込んだものと考えられる。
こういった運営者側のアルゴリズムの工夫に加え、Amazonでは以下のように第三者が不自然なユーザー評価がないかを検証し、勝手に(?)評価点を修正して計算してくれるサイトがある。
• サクラチェッカー
• ReviewMeta
例えばサクラチェッカーでは計算にあたって、以下の6項目を“サクラ”の判別に使っているとされる。
• 価格、製品:異常な値引率、商品名など
• ショップ:発送地域、電話番号不掲載など
• ショップレビュー:急激なショップレビューの悪化 → オープニングで不正レビューを自作自演でやっている業者など
• レビュー分布/履歴:自然ではないレビュー分布、レビュー件数の履歴
• レビュー日付:バイト募集期間による極端な日付の偏り
• レビュー・レビュアー→ レビュー本文の怪しさ、レビュアー自身の怪しさなど
(出典:サクラチェッカーFAQ)
評価点に関する情報開示による工夫
評価点自体の計算方法の改善は大事なテーマだが、一方でデータの特徴を代表値一つに集約すること自体にはそもそも限界がある。いくらアルゴリズムを改善したとしてもデータを全て知っている運営者と、ユーザー、あるいは飲食店などの評価される側との情報の非対称性はいかんともし難い。
このギャップを少しでも埋めるためにはユーザー評価点に関する情報開示を増すといった方策も考えられる。データの特徴をとらえる場合、代表値に加え、データの散らばりや分布の様子を見るのがデータ分析では常道だ。
ただ、大学院の授業などの経験で痛感するのは、分析というとほとんどの人が平均値の計算で終わってしまう点だ。もったいない。散らばりや分布に目配りすることは、比較的簡単にデータ分析で差別化できるスイートスポットの一つだ。
例えば映画の評価サイトであるIMDbの情報開示は参考になる。
IMDbでは映画の10段階でのユーザーレビューに対して全体での単純平均、加重平均、中央値といった代表値もちろんのこと、セグメント別、さらにヒストグラムを使って評価点の分布状況を開示していて、情報量が圧倒的に多い。
具体的に「スター・ウォーズ/最後のジェダイ」の評価を見てみよう。
平均はほぼ7点だが、分布からは平均点ではわからなかった、高評価のユーザーがいる一方、1点という酷評しているユーザーが一定いて好みがわかれていることが伺える。
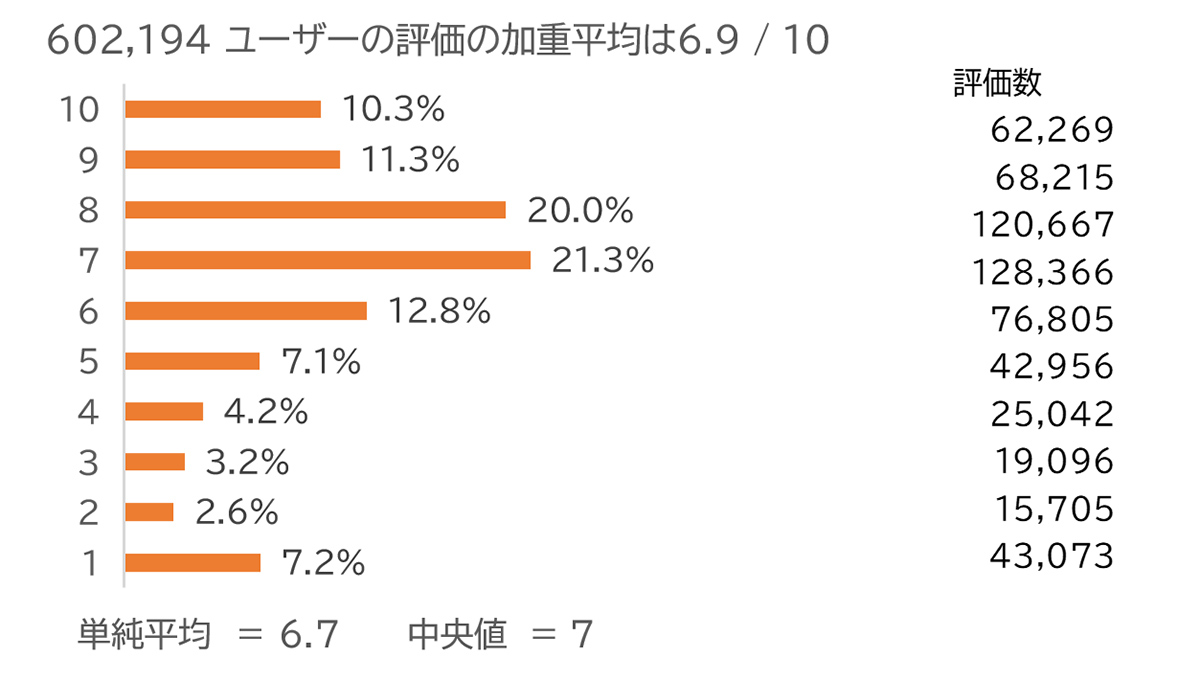
(IMDb より筆者作成、データは2022年1月末の執筆時点)
たかが平均、されど平均
実は食べログでも評価点のヒストグラムは開示されている。
評価点に関する情報開示を増やすことは方向としては正しいのだが、限られた時間でお店を選択する多くのユーザーにとっては情報量が多すぎると比較しづらい。脳の負担が大きすぎる。やはりなんと言っても比較しやすい平均値をはじめとする代表値は便利なのだ。
たかが平均、されど平均である。
食べログのケースでは、多くの有志の分析もあり(「『食べログ独自の評価基準』の機械学習による再現を試みる」などが一例)、おそらく巷間で騒がれるような食べログ側の不正操作の可能性はかなり低いと思われる。
それでもアルゴリズムが開示されず、情報に非対称性がある限り、不正をしているのではないか、という疑いの目は避けられないだろう。ユーザーの影響度をどのように計算しているのか、レビューの数によってフィルタリングをしているのかなど、可能な限り計算方法についての情報開示を進めるしか方策はないように思える。
たとえ、それがアルゴリズムの裏をかこうとする不正者とのイタチごっこになるとしても評価点への信頼を回復することが最優先だろう。
食べログの評価点を題材に、データの特徴をどのように捉えるか、代表値をどのように定めるかについて見てきた。平均値の奥深さ(?)を少しでも感じていただければ幸いである。
※定量分析の一連のプロセスなどの基礎を学びたい方には、グロービス経営大学院の講座「ビジネス・アナリティクス」がおすすめです。









































.jpg?fm=webp&fit=clip&w=720)
.png?fm=webp&fit=clip&w=720)



